This post is inspired by Coralie’s recent blog post, “Meta-analysis terminology can be confusing”, in which she untangles a range of commonly used, misused, and confused terms in meta-analysis—such as subgroup analysis, moderator analysis, meta-regression, fixed-effect vs fixed-effects models, and multivariate.
These certainly warrant clarification. But what about the terminology for the underlying data—could that be just as confusing?
What is “meta-data”?
There are many definitions of meta-data (or metadata), but most describe it as “the information that defines and describes data” (ABS). Since information is also a form of data, meta-data itself can have meta-data… which can have more meta-data… and so on. Conversely, a dataset can include meta-data, which itself may include even deeper layers of meta-data. This creates a kind of conceptual circularity that adds to the confusion—especially in the context of meta-analysis (and systematic reviews of all sorts).
Does meta-analysis use meta-data?
Yes—but not always in the way people expect.
It is common to assume that meta-data simply refers to the dataset compiled and analyzed in a meta-analysis, especially since both terms contain the prefix “meta” and deal with data from primary studies. As a result, when researchers are asked to share both their data and meta-data, they often upload only the dataset itself. However, in this context, meta-data refers specifically to the description of the dataset: a detailed explanation of the variables, their definitions, units, data structure, etc. But this may also contain some information that can be considered meta-data, contributing to the confusion.
Around meta-analysis (16): meta-data, metadata, and more meta confusion
By Malgorzata (Losia) Lagisz – June 28, 2025
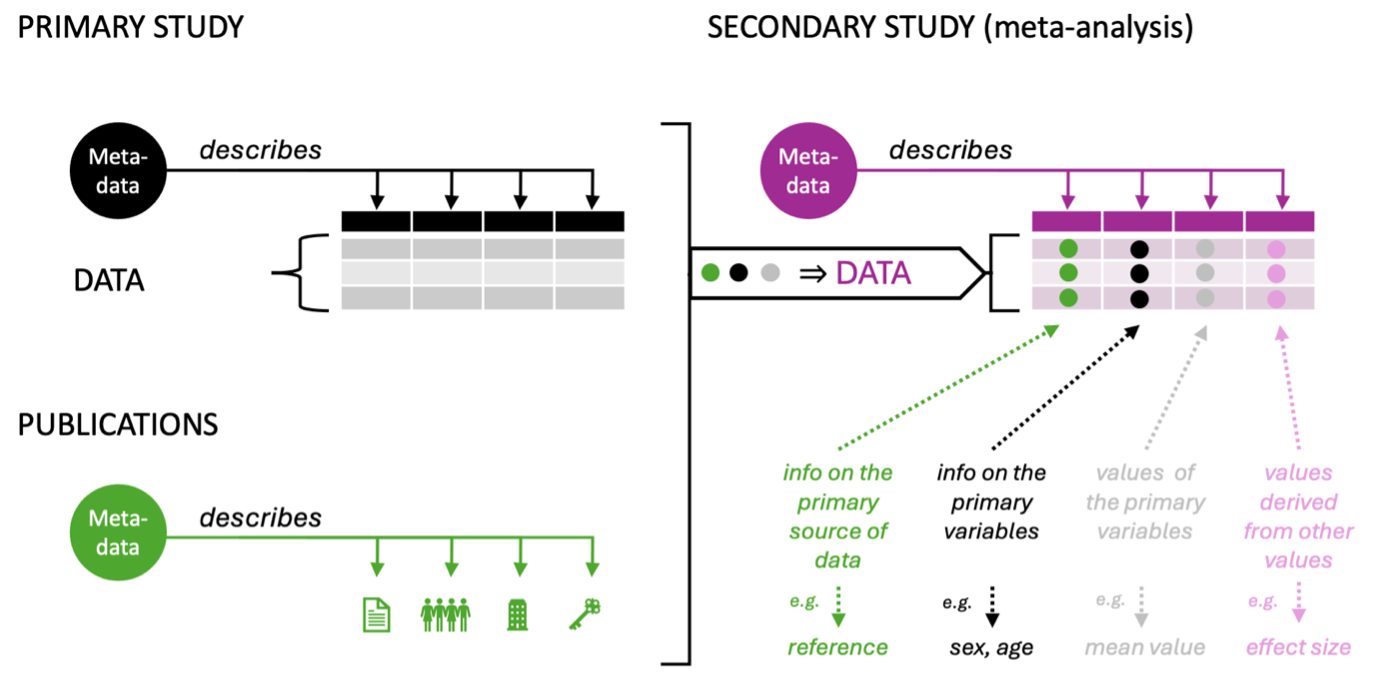
Visualising layers of meta-data in meta-analyses
What counts as “data” or “meta-data” depends on the context (see my diagram above). In a primary empirical study, the data might consist of field or lab measurements of things, humans, or systems, while the meta-data includes descriptions of the variables in that spreadsheet (black parts of the diagram above).
But once a primary study is published (or shared), it gains another layer of meta-data: title, abstract, publication date, author names, affiliations, etc. This is the meta-data librarians and other information specialists work with (green parts of the diagram above).
In a secondary study, such as a meta-analysis or systematic review, you typically compile not only data of primary studies (selected results and their descriptors), but also some of their meta-data (e.g., study-level characteristics such as study reference, title, authors, journal, DOI, etc.), and then also generate new data for your synthesis (e.g., recalculated effect sizes). The resulting dataset is a layered mix of data and meta-data from different sources and levels.
What to do in practice
In practice, for a meta-analysis (and systematic reviews or other secondary studies) use terminology consistently in the context of your study: call your dataset "data", and description of your dataset "meta-data" (purple/plum, NOT pink, parts of the diagram above). You can still acknowledge that your data contains some meta-data from underlying primary studies (e.g. information describing the publications).
Why it matters
Conceptual complexity—and the commonly inconsistent use of terminology—may partially explain why appropriate meta-data is often missing or poorly documented in shared datasets from meta-analyses (and various types of systematic reviews). When people are asked to share meta-data--but they think this is just their dataset (data)--they only share the dataset, without description of all variables (meta-data). But without complete and well-structured meta-data (the descriptions of data), it becomes difficult to interpret the dataset (the data), let alone reuse it or reproduce the analyses. Transparent and clear meta-data (descriptions of data = dataset) is crucial for making meta-analyses truly open and reusable.
NOTE:
You can find earlier blog posts from my “Around meta-analysis” series archived on my personal website.